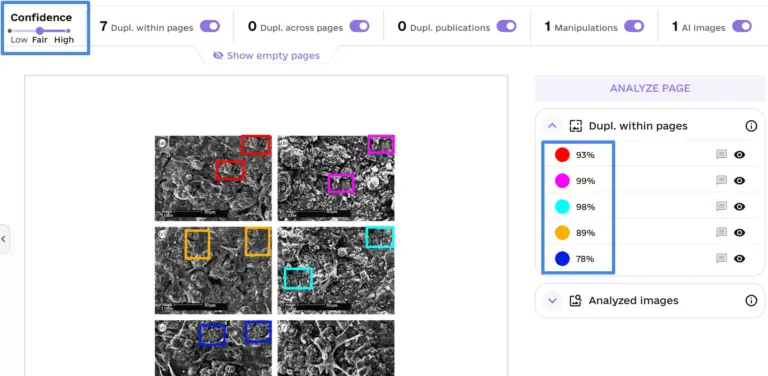
Introducing: Confidence Scores

Not every duplicate is problematic: experts differentiate between appropriate and inappropriate cases. Appropriate duplicates are not research integrity issues, while inappropriate ones are integrity issues and can lead to a paper’s rejection, correction, or retraction. With our latest update, we display confidence scores from 0% to 100% for each detected duplicate. A high confidence (e.g., 99% in the example above) means that the finding is likely inappropriate. In contrast, a low score (e.g., 2% in the “merge” duplicate example) means the case is likely appropriate. The confidence score helps you to quickly separate between relevant and irrelevant cases.
New user interface
In the updated user interface, each duplicate is accompanied by a confidence score. A slider can be used to filter duplicates based on a specific confidence threshold. We differentiate between three ranges: low (0%-32%), fair (33%-65%), and high (66%-100%). By default, the slider starts at 33%, displaying fair and high cases. We recommend reviewing all fair and high cases. To deepen your investigation, you can examine duplicates in the low range by adjusting the slider. Based on the current filters, we summarize how many findings are currently shown/hidden. All currently shown findings are included in the PDF report.
Appropriate vs. inappropriate
We compute the confidence/relevancy of a duplicate using several features. Features include image similarity, image class (e.g., radiology, spot image, or western blot), duplicate type (e.g., duplicate inside the same paper or across papers), and many others. Based on these features, we derive a confidence score for each duplicate, representing the appropriateness of a duplicate. We measured the effectiveness of our algorithm on inappropriate duplicates posted on PubPeer mixed with appropriate ones from randomly sampled publications.
Appropriate examples are versatile, such as two images of the same microscopy image with different zoom factors, images with different color channel overlays (merge), or radiology images showing a brain scan with different color injections. We analyzed 5068 duplicates, consisting of 1797 inappropriate and 3271 appropriate duplicates. Of the 1797 inappropriate duplicates, we correctly classified 1733 cases (i.e., we predicted a confidence within the range of 33%-100%). Of the 3271 appropriate duplicates, we correctly classified 2936 cases (i.e., confidence in 0%-33%).
Bulk processing
The differentiation between low, fair, and high-confidence duplicates can help efficiently bulk process large paper volumes. By knowing which papers contain duplicates with a fair or high chance of being inappropriate, users can specifically investigate these duplicates. Our API allows bulk processing of hundreds of papers, and during the next week, we will update our API* to include information on whether low, fair, or high-confidence findings were detected in the scanned documents. Even when scanning hundreds of papers, only a small manual effort is necessary to detect inappropriate duplicates at scale.
Frequently asked questions
How accurate is Imagetwin compared to other image integrity tools?
Imagetwin’s confidence scoring system was validated on 5,068 duplicates combining confirmed inappropriate cases from PubPeer with appropriate duplicates from randomly sampled publications. Of 1,797 inappropriate duplicates, 1,733 were correctly classified as fair or high confidence. The system distinguishes between appropriate duplicates (such as the same image shown at different zoom levels) and genuinely problematic ones, reducing false positives and manual review time. Western blot duplicate detection achieves 90% accuracy on verified PubPeer cases, with a 1.7% false positive rate on manipulation detection. Main competitor does not publish equivalent validation figures publicly.
Is there software that can catch duplicate images in research without generating excessive false positives?
Yes. Imagetwin uses confidence scoring from 0% to 100% to separate appropriate duplicates from problematic ones, so editors are not overwhelmed by irrelevant flags. A high confidence score indicates a likely inappropriate duplicate; a low score indicates a likely appropriate reuse such as a different color channel overlay or zoom factor. Users can adjust a threshold slider to filter results and focus investigation on high-priority cases. This makes bulk screening of hundreds of papers via API practical, with only a small manual review effort required.
What is the best tool for detecting image duplication in research at scale?
Imagetwin is built for high-volume screening. Its API supports bulk processing of hundreds of papers, returning confidence-scored results that distinguish inappropriate duplicates from appropriate reuse. It screens against a database of 160M+ published scientific images, achieves 90% accuracy on Western blot duplicates, and integrates into ScholarOne, Editorial Manager, Wiley’s Research Exchange, Signals, Integra’s EditorialPilot, CACTUS’s Paperpal Preflight, Rivyr, and Clear Skies’ Oversight. It is trusted by Wiley, Karger, Sage, ASM, and FASEB.



