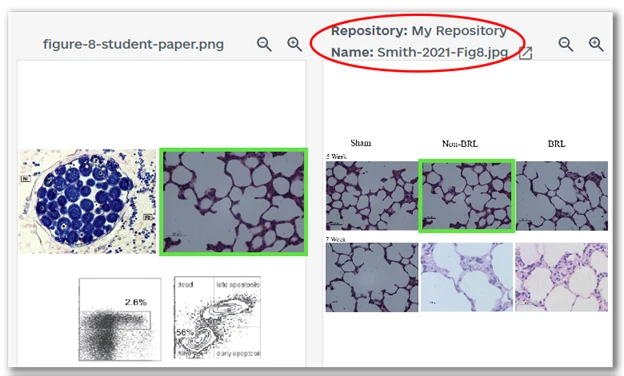
We built this update with two goals in mind: improving detection performance and making results more transparent and actionable.
Here are some of the most important changes:
Stronger Model Performance
We switched to a more recent state-of-the-art vision model and trained it on much larger and more diverse datasets. This includes thousands of AI-generated images created through text-to-image and image-to-image workflows.Realistic Training Pipeline
Our team built a new pipeline that turns real images from published papers into modified AI versions designed to look realistic. This approach has significantly improved detection robustness across many scientific image types.Expanded Model Coverage
Detection now recognises images generated by a wider range of tools, including:Firefly (Adobe’s AI system used in Photoshop and other Adobe products)
DALL·E 3 (previously used in ChatGPT and widely adopted over the past few years)
Stable Diffusion (versions 1.6, 3.5, and XL)
Internet-generated images (AI art found through search engines or stock libraries)
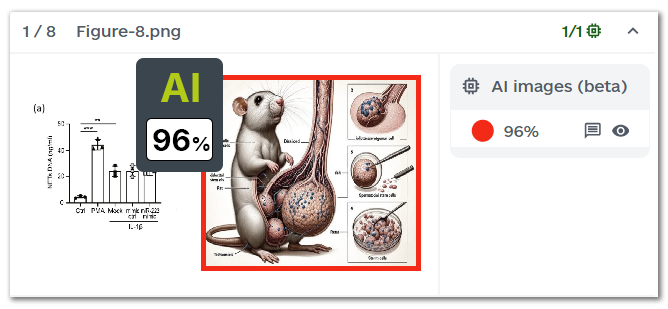
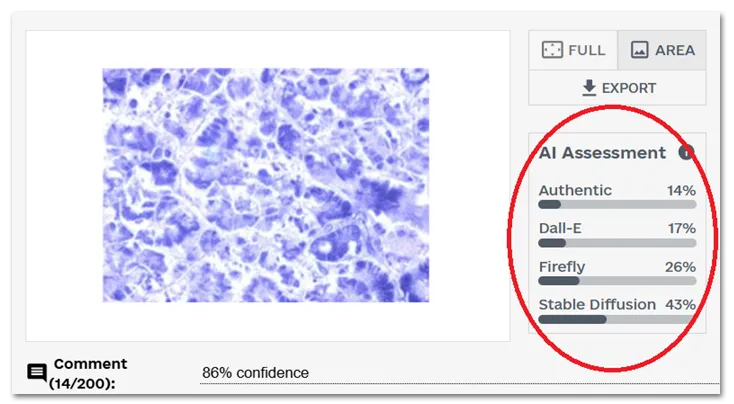
Model Attribution for More Transparency
Previously, users only received a confidence score indicating the likelihood an image was AI-generated. Now, each flagged image includes an “AI assessment” showing a distribution of which generator the system believes was used. For example, you may see a score indicating higher probability of generation by DALL·E compared to Firefly or Stable Diffusion. This gives reviewers and editors more context to evaluate flagged cases.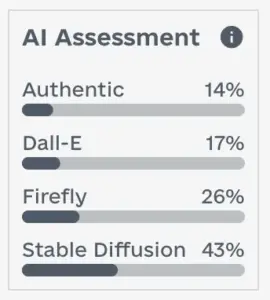
Improved User Interface
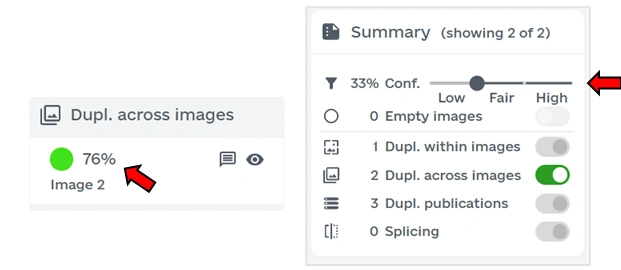
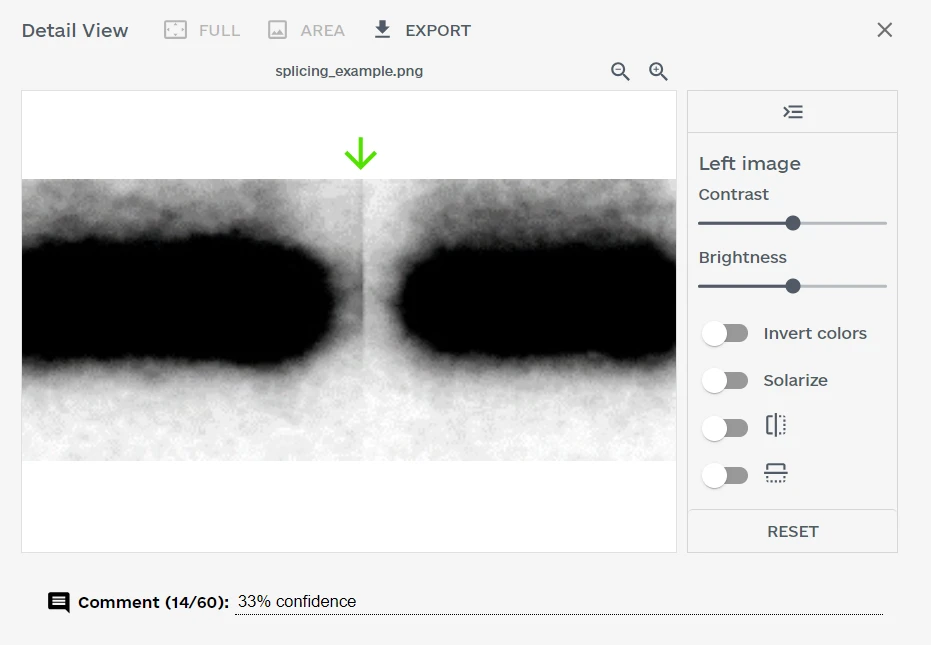
Clicking on any detected issue in the overview now opens the detail view displaying the confidence score and the likely distribution across AI models.